
HTTP to protokół, który stanowi fundament współczesnego internetu.
Gdzie znajdziesz HTTP? Krótka odpowiedź: prawie wszędzie!
Czytając ten post, korzystasz z HTTP właśnie w tym momencie. Tak samo przeglądając Facebooka, Youtube, czytając strony internetowe, a nawet używając większości aplikacji mobilnych. Wszędzie tam pobierasz dane przez HTTP.
HTTP powstał jako sposób przesyłania stron internetowych, ale teraz jest używany do bardzo wielu zastosowań: przekazywania danych do aplikacji frontendowych, mobilnych, pobierania plików i również do komunikacji wewnętrznej pomiędzy serwisami w dużych systemach.
Film
Wszystkie informacje w tym artykule, razem z praktyczną demonstracją, znajdziesz w filmie traktującym o HTTP 👇
Jak wygląda komunikacja?
HTTP to protokół tekstowy działający na połączeniu TCP. Po otwarciu połączenia, przeglądarka wysyła odpowiednio sformatowane zapytanie do serwera, na które ten wysyła odpowiedź, również w odpowiednim formacie. Sesja HTTP składa się z serii takich pytań i odpowiedzi.
Zapytanie
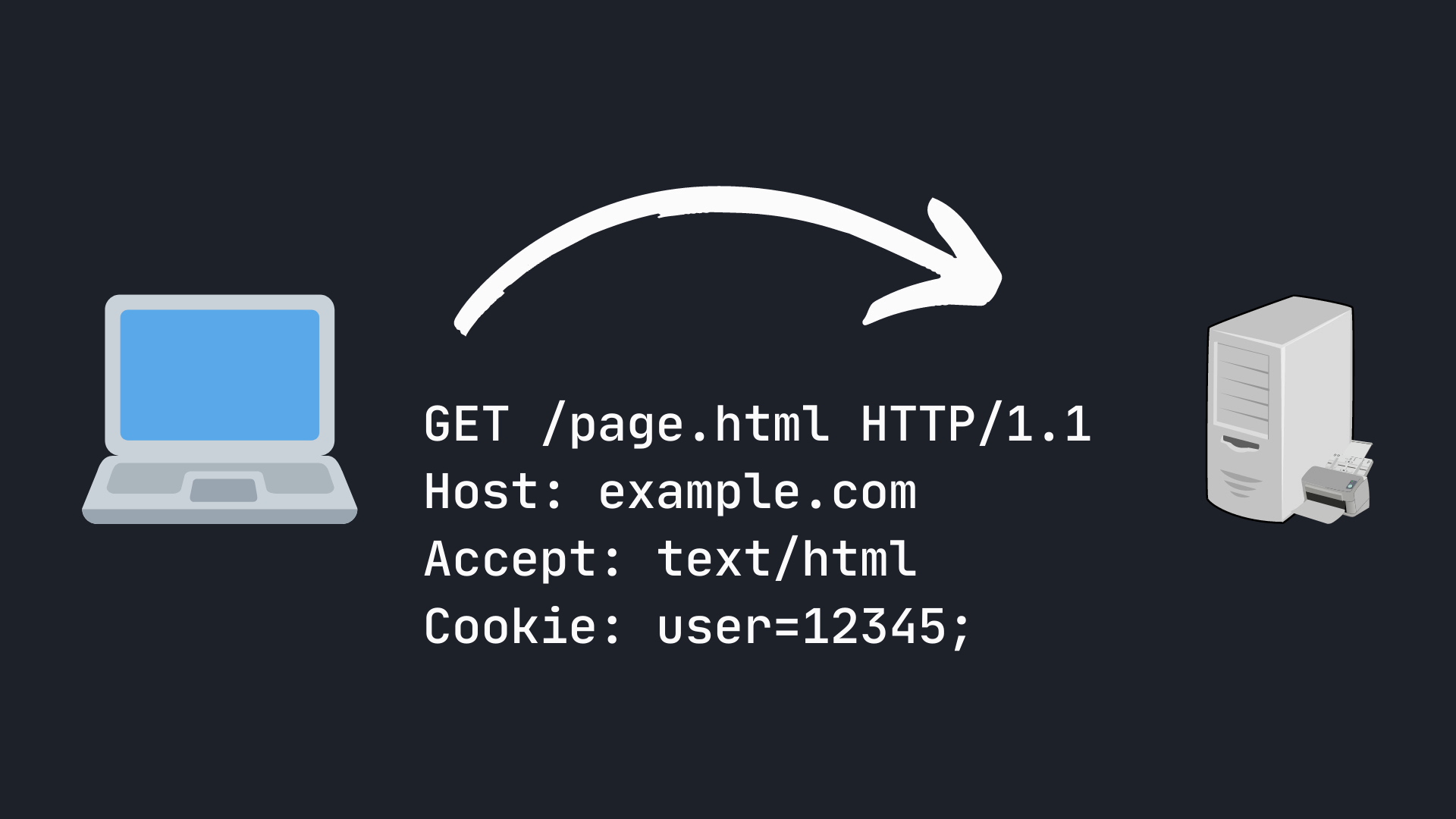
Zapytanie HTTP wygląda tak:
GET /page.html HTTP/1.1
Host: example.com
Accept: text/html
Cookie: user_id=12345;
Na pierwszej pozycji znajduje się nazwa metody, np. GET (do prostego wyświetlenia strony) lub POST (do wysłania danych do serwera).
Pełną listę metod HTTP znajdziesz tutaj.
Za nią mamy ścieżkę do strony, którą chcemy pobrać (tutaj /page.html). Na końcu pierwszej linii podajemy
jeszcze wersję protokołu, której używamy (tutaj HTTP/1.1).
W następnych liniach podajemy nagłówki zapytania. Ja podaję Host, czyli domenę strony, do której się odwołuję, bo jeden serwer może obsługiwać kilka stron na raz. Drugim nagłówkiem, który podałem jest Accept, który podpowiada serwerowi, jaki format danych chciałbym dostać w odpowiedzi (tutaj stronę w HTMLu). W nagłówku Cookie przeglądarka wysyła pliki cookies, które ma zapisane dla danej strony.
Listę nagłówków HTTP znajdziesz tutaj.
Opcjonalnie, możemy podać jeszcze pustą linię i za nią dodać treść zapytania, czyli dane, które chcemy wysłać do serwera. Nie dotyczy to zapytań typu GET, jedynie POST, PUT itd.
Zapytanie kończy się dwiema pustymi liniami. UWAGA: znakami końca linii w HTTP jest kombinacja CRLF (inaczej \r\n).
Trzeba na to uważać, bo w systemach Linuxowych domyślnym znakiem końca linii jest samo LF (\n).
Odpowiedź
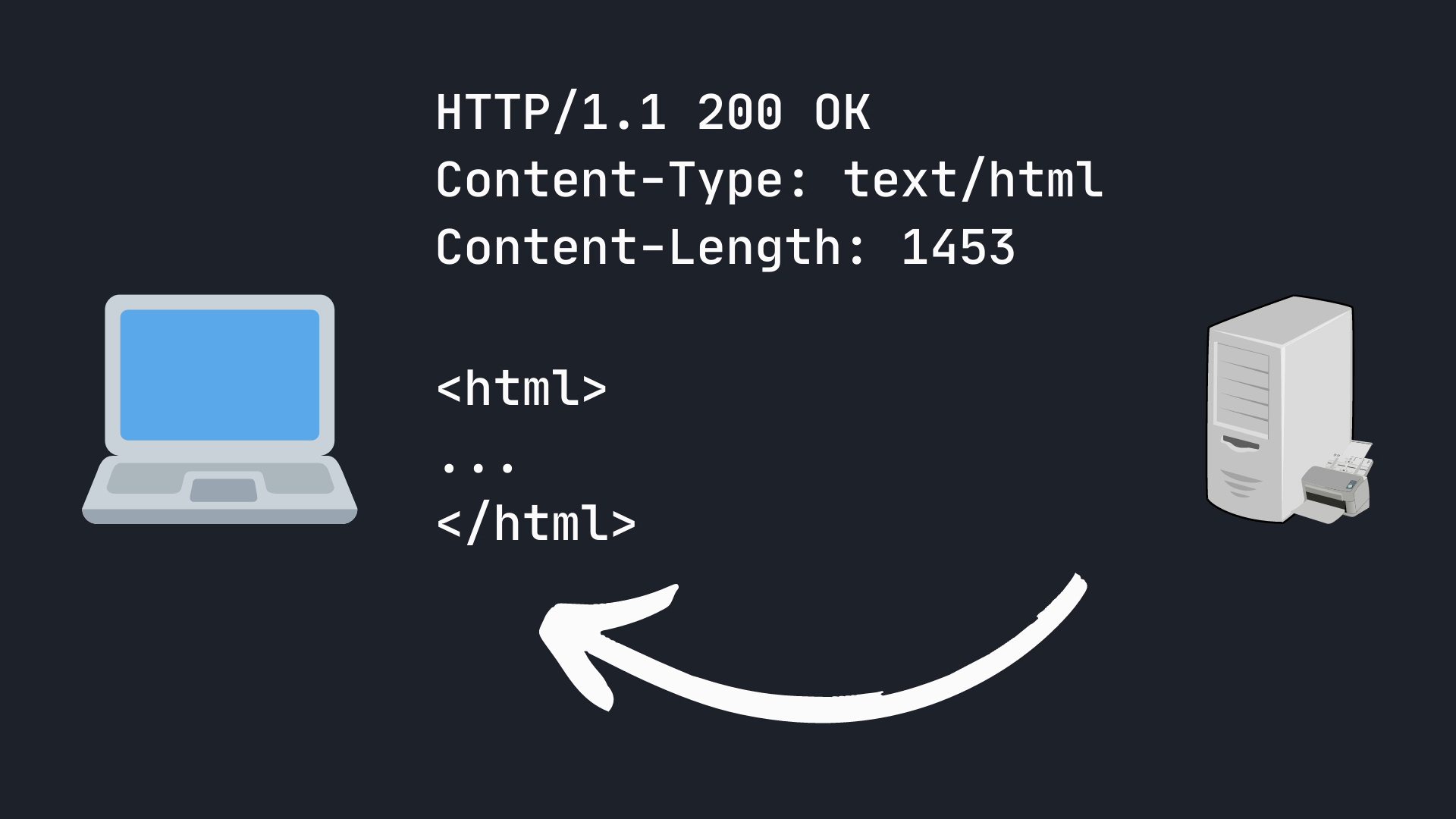
Na takie zapytanie serwer odpowiada w następujący sposób:
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8
Content-Length: 1453
Set-Cookie: visited=1;
<html>...</html>
W pierwszej linii mamy oznaczenie wersji protokołu, identycznie jak w zapytaniu, a po nim kod i opis statusu odpowiedzi, np. 200 OK, 404 Not Found czy 500 Internal Server Error (które na pewno są Ci znane :}).
Pełną listę kodów znajdziesz tutaj.
Po pierwszej linii następują nagłówki odpowiedzi. W moim wypadku Content-Type, czyli format i kodowanie treści odpowiedzi; Content-Length — jej długość; i Set-Cookie, czyli polecenie zapisania cookiesa w przeglądarce.
Po nagłówkach znajduje się pusta linia, a za nią sama treść odpowiedzi. W tym przypadku będzie to jakaś strona w HTMLu. Może to być też na przykład plik, który pobierasz albo dane w JSONie, jeżeli odpytujesz jakieś API.
HTTP w praktyce
Jeżeli chcesz podejrzeć, jak wygląda komunikacja po HTTP, możesz spojrzeć w narzędzia deweloperskie w swojej przeglądarce, zwykle otwierane klawiszem F12. W zakładce Network (Sieć) pojawi się lista wszystkich zapytań, które wykonała przeglądarka (jeżeli jest pusta, musisz odświeżyć stronę). Kiedy wejdziesz w szczegóły takiej komunikacji, zobaczysz nagłówki oraz treść zapytania i odpowiedzi.
Inna opcja to użycie programu Wireshark, który pozwala “podsłuchać” połączenia wykonywane przez Twój komputer.
Jeszcze inna opcja to program Netcat. Otwiera on połączenie TCP z wybranym hostem i pozwala wysyłać nim dowolne dane. Dzięki temu możemy ręcznie wpisać zapytanie lub odpowiedź HTTP.
Zapytanie HTTP w Netcat
Poleceniem nc example.com 80 mogę połączyć się ze stroną example.com na porcie 80, czyli domyślnym porcie dla HTTP.
Teraz mogę wpisać moje zapytanie, na które powinienem otrzymać odpowiedź z zawartością strony głównej.
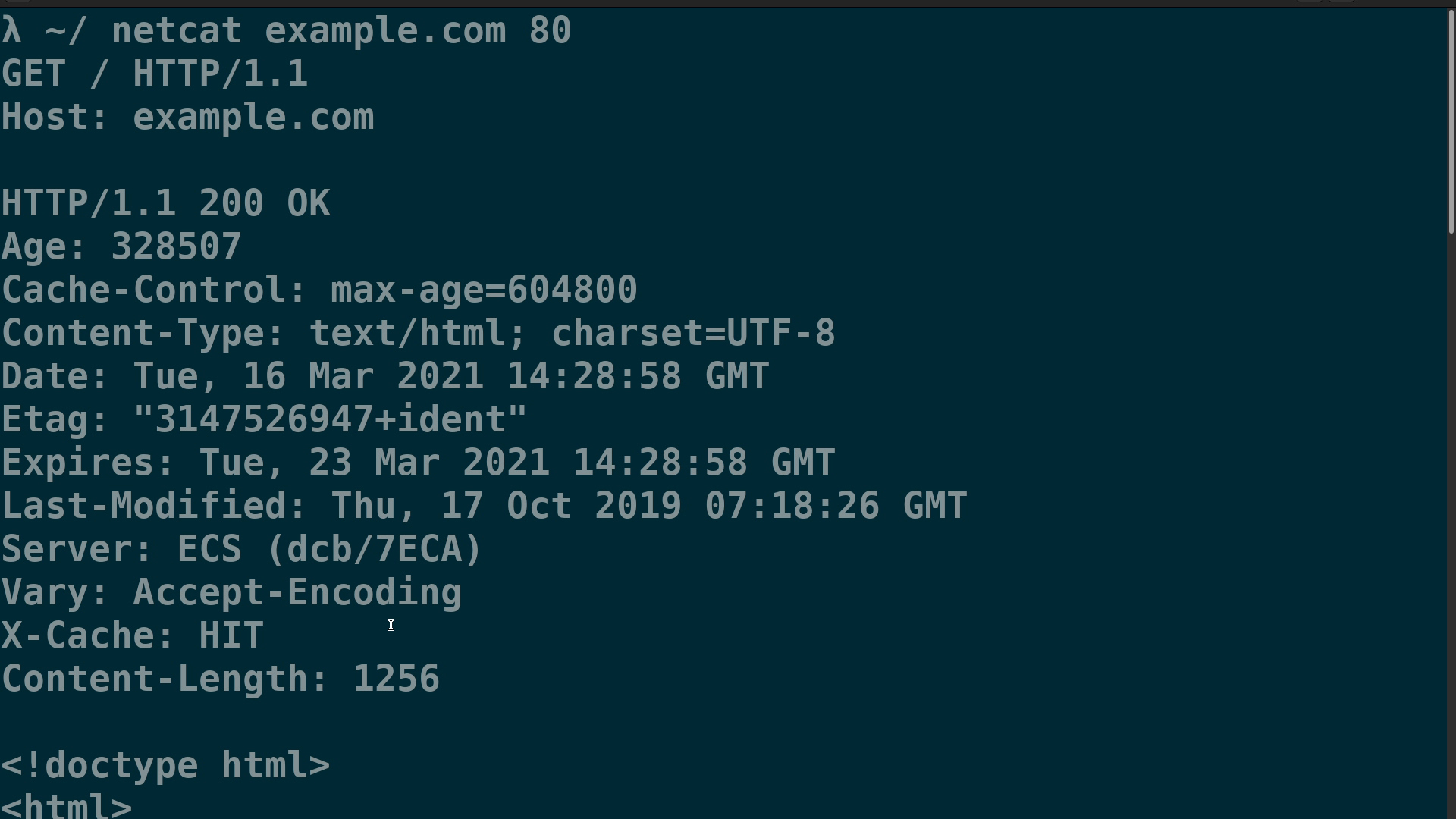
W ten sposób staję się klientem HTTP, tak samo jakbym to ja był Firefoxem albo Chromem :}
UWAGA: musisz wybrać stronę, która używa nieszyfrowanej wersji HTTP, a nie HTTPS — inaczej nie będziesz w stanie podejrzeć treści danych wymienianych między Twoim komputerem a serwerem. Dobrym wyborem będzie example.com, czyli domena specjalnie przeznaczona do celów testowych i dokumentacji. Ta strona jest serwowana nieszyfrowanym HTTP, więc możemy łatwo podejrzeć komunikację.
Serwer HTTP w Netcat
Mogę też odwrócić sytuację i udawać serwer strony internetowej. Poniższym poleceniem uruchamiam Netcat w trybie oczekiwania na połączenie na porcie 4000.
$ nc -l 4000
Jeżeli teraz wejdę w przeglądarce na adres http://localhost:4000, to ona otworzy połączenie z Netcatem i wyśle
zapytanie. Zobaczę je w terminalu z Netcatem i mogę na nie odpowiedzieć.
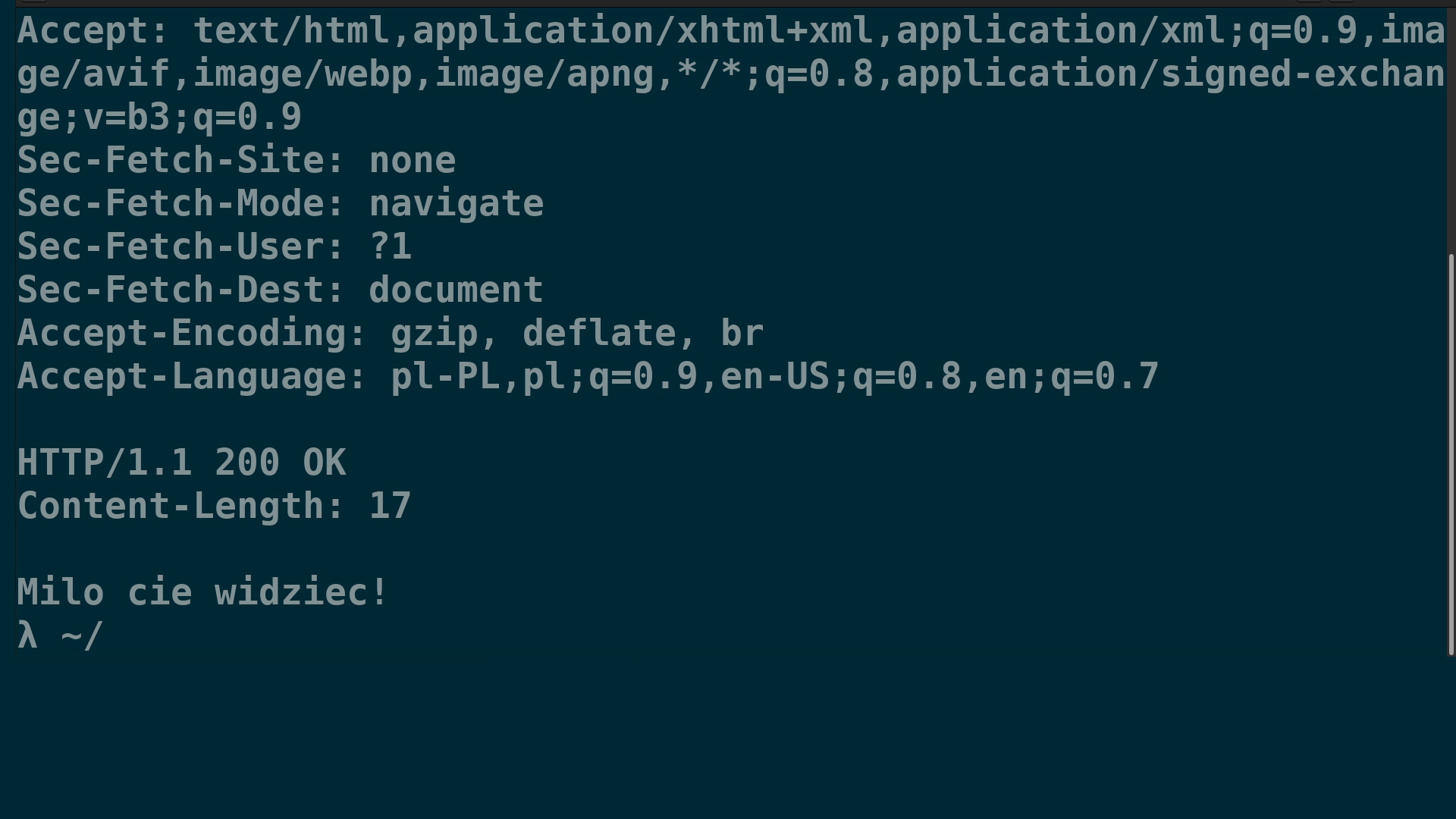
Żeby przeglądarka wiedziała, że otrzymała już całość danych, które chcę wysłać, muszę zrobić jedną z dwóch rzeczy. Albo
podam nagłówek Content-Length, z długością danych, które będę wysyłał (nie wliczając nagłówków); albo zamknę
połączenie
po wysłaniu wszystkich danych (np. skrótem CTRL-C zabiję proces Netcata).
Tekst lub HTML, który podam w treści odpowiedzi, przeglądarka wyświetli jako stronę internetową. Sukces!
Zapisz się na mailing!
Na dzisiaj to tyle. Ah, ale się rozpisałem :} Mam nadzieję, że ta wiedza pomoże Ci w Twojej wędrówce po świecie Backend Developerów.
Jeżeli interesuje Cię tworzenie aplikacji webowych, zapisz się na mailing, na którym oryginalnie pojawił się ten artykuł.
👋 Do usłyszenia, Jan